> 转换变量
### 转换命令日志
在 “数据> 转换” 标签页中应用的所有转换都可被记录。例如,如果你对数值变量应用 “自然对数(Ln (natural log))” 转换,点击 `存储` 按钮后,以下代码会生成并显示在屏幕底部的 “转换命令日志” 窗口中。
```r
## transform variable
diamonds <- mutate_ext(
diamonds,
.vars = vars(price, carat),
.funs = log,
.ext = "_ln"
)
```
如果你想用新的类似数据重新运行报告,这一功能至关重要。更重要的是,它记录了数据转换和结果生成的步骤,即你的工作现在具有可重复性。
要将命令日志窗口中的命令添加到“报告> Rmd”中的报告,点击图标。
### 过滤数据
即使已指定过滤器,它对 “数据> 转换” 中的(大多数)函数也无效。要基于过滤器创建新数据集,请导航至“数据> 查看”标签页并点击 `存储` 按钮。或者,要基于过滤器创建新数据集,从 `转换类型`下拉菜单中选择 `拆分数据 > 留存样本`。
### 隐藏汇总
对于较大的数据集,或不需要汇总信息时,在选择转换类型并指定数据修改方式前,点击 `隐藏汇总` 会很有用。如果你想查看汇总,请确保未勾选 `隐藏汇总`。
### 修改变量
#### 分箱
当你想创建多个五分位数 / 十分位数 /... 变量时,“分箱(Bin)” 命令是下文讨论的`xtile`命令的便捷功能。要计算五分位数,在 “分箱数量(Nr bins)” 中输入`5`。“反转(reverse)” 选项会将 1 替换为 5、2 替换为 4……5 替换为 1。为新变量选择合适的扩展名。
#### 更改类型
从 “转换类型” 下拉菜单中选择 `类型` 后,会显示另一个下拉菜单,可用于更改一个或多个变量的类型(或类别)。例如,你可以将整数类型的变量转换为因子类型的变量。点击 “存储” 按钮将更改应用到数据集。以下是转换选项的说明:
1. 转换为因子(As factor):将变量转换为因子类型(即分类变量)
2. 转换为数值(As number):将变量转换为数值类型
3. 转换为整数(As integer):将变量转换为整数类型
4. 转换为字符(As character):将变量转换为字符类型(即字符串)
5. 转换为时间序列(As times series):将变量转换为 ts 类型
6. 转换为日期(月 - 日 - 年)(As date (mdy)):如果日期格式为月 - 日 - 年,将变量转换为日期类型
7. 转换为日期(日 - 月 - 年)(As date (dmy)):如果日期格式为日 - 月 - 年,将变量转换为日期类型
8. 转换为日期(年 - 月 - 日)(As date (ymd)):如果日期格式为年 - 月 - 日,将变量转换为日期类型
9. 转换为日期 / 时间(月 - 日 - 年 - 时 - 分 - 秒)(As date/time (mdy_hms)):如果日期时间格式为月 - 日 - 年 - 时 - 分 - 秒,将变量转换为日期时间类型
10. 转换为日期 / 时间(月 - 日 - 年 - 时 - 分)(As date/time (mdy_hm)):如果日期时间格式为月 - 日 - 年 - 时 - 分,将变量转换为日期时间类型
11. 转换为日期 / 时间(日 - 月 - 年 - 时 - 分 - 秒)(As date/time (dmy_hms)):如果日期时间格式为日 - 月 - 年 - 时 - 分 - 秒,将变量转换为日期时间类型
12. 转换为日期 / 时间(日 - 月 - 年 - 时 - 分)(As date/time (dmy_hm)):如果日期时间格式为日 - 月 - 年 - 时 - 分,将变量转换为日期时间类型
13. 转换为日期 / 时间(年 - 月 - 日 - 时 - 分 - 秒)(As date/time (ymd_hms)):如果日期时间格式为年 - 月 - 日 - 时 - 分 - 秒,将变量转换为日期时间类型
14. 转换为日期 / 时间(年 - 月 - 日 - 时 - 分)(As date/time (ymd_hm)):如果日期时间格式为年 - 月 - 日 - 时 - 分,将变量转换为日期时间类型
**注意:** 将变量转换为`ts`类型(即时间序列)时,至少应指定起始周期和数据频率。例如,对于从一年第 4 周开始的周数据,在 “起始周期(Start period)” 中输入`4`,并将 “频率(Frequency)” 设为`52`。
#### 标准化
从 “转换类型” 下拉菜单中选择 `标准化` 以标准化一个或多个变量。例如,在钻石数据中,我们可能希望按克拉数表示钻石价格。在 `选择变量` 框中选择`price`,并选择`carat`作为 `标准化变量`。主面板中会显示新变量(如`price_carat`)的汇总统计量。点击 “存储” 按钮将更改应用到数据。
#### 重编码
要使用重编码功能,选择你想要更改的变量,然后从 “转换类型” 下拉菜单中选择 “重编码(Recode)”。提供一个或多个重编码命令(用`;`分隔),按回车查看变量更改信息。注意,你可以在 “重编码变量名称(Recoded variable name)” 输入框中指定重编码后变量的名称(按回车提交更改)。最后,点击 “存储” 将重编码后的变量添加到数据中。以下是一些示例:
1. 将 20 以下的值设为`低(Low)`,其他设为`高(High)`
```r
lo:20 = 'Low'; else = 'High'
```
2. 将 20 以上的值设为`高(High)`,其他设为`低(Low)`
```r
20:hi = 'High'; else = 'Low'
```
3. 将 1-12 的值设为`A`,13-24 的值设为`B`,其余设为`C`
```r
1:12 = 'A'; 13:24 = 'B'; else = 'C'
```
4. 为“基础> 表格 > 交叉表”分析合并年龄类别。在下方示例中,`<25`和`25-34`重编码为`<35`,`35-44`和`45-54`重编码为`35-54`,`55-64`和`>64`重编码为`>54`
```r
'<25' = '<35'; '25-34' = '<35'; '35-44' = '35-54'; '45-54' = '35-54'; '55-64' = '>54'; '>64' = '>54'
```
5. 要在后续分析中排除特定值(如数据中的异常值),可将其重编码为缺失值。例如,如果我们想从名为`sales`的变量中移除等于 400 的最大值,(1)在 `选择变量` 框中选择变量`sales`,在 `重编码` 框中输入以下命令。按回车并点击 “存储” 将重编码后的变量添加到数据中
```r
400 = NA
```
5. 要将特定数值(如克拉数)重编码为新值,(1)在 `选择变量` 框中选择变量`carat`,在 `重编码` 框中输入以下命令,将克拉数大于或等于 2 的值设为 2。按回车并点击 `存储` 将重编码后的变量添加到数据中
```r
2:hi = 2
```
**注意:** 使用重编码功能时,变量标签中不要使用`=`(例如`50:hi = '>= 50'`),这会导致错误。
#### 重新排序或移除水平
如果 `选择变量` 中选中了单个因子类型变量,从`转换类型` 下拉菜单中选择 `移除/重新排序级别` 可重新排序和 / 或移除水平。拖放水平可重新排序,点击×可移除水平。注意,默认情况下,移除一个或多个水平会在数据中引入缺失值。如果你希望将移除的水平重编码为新水平(例如 “其他”),只需在`替换水平名称`输入框中输入 “其他” 并按回车。如果生成的因子水平符合预期,点击`存储` 应用更改。要暂时从数据中排除水平,使用 `过滤数据`框(参见“数据> 查看”标签页中的帮助文件)。
#### 重命名
从`转换类型` 下拉菜单中选择`重命名`,选择一个或多个变量,在 `重命名` 框中输入它们的新名称(用`,`分隔)。按回车在屏幕上查看重命名后变量的汇总,点击 `存储` 更改数据中的变量名称。
#### 替换
如果想用新变量(例如通过`创建、转换、剪贴板` 等创建的变量)替换数据中的现有变量,从 `转换类型` 下拉菜单中选择 `替换`。选择一个或多个要覆盖的变量和相同数量的替换变量。点击 `存储` 修改数据。
#### 转换
从`转换类型` 下拉菜单中选择 `转换` 后,会显示另一个下拉菜单,可用于对数据中的一个或多个变量应用常见转换。例如,要对变量取自然对数,选择要转换的变量,从 `应用函数` 下拉菜单中选择 `自然对数`。转换后的变量会带有 `变量名称扩展名` 输入框中指定的扩展名(例如`_ln`)。更改扩展名后请务必按回车。点击 `存储` 按钮将(更改后的)变量添加到数据集。以下是 Radiant 中包含的转换函数说明:
1. 自然对数(Ln):创建所选变量的自然对数转换版本(即 log (x) 或 ln (x))
2. 平方(Square):变量自乘(即 x² 或 square (x))
3. 平方根(Square-root):取变量的平方根(即 x^0.5)
4. 绝对值(Absolute):变量的绝对值(即 abs (x))
5. 中心化(Center):创建均值为 0 的新变量(即 x - mean (x))
6. 标准化(Standardize):创建均值为 0、标准差为 1 的新变量(即 (x - mean (x))/sd (x))
7. 倒数(Inverse):1/x
### 创建新变量
#### 剪贴板
尽管不推荐,但你可以在电子表格(如 Excel 或 Google 表格)中处理数据,再将数据复制粘贴回 Radiant。如果原始数据不在电子表格中,使用“数据> 管理”中的剪贴板功能将其粘贴到电子表格,或点击“数据> 查看”标签页右上角的下载图标。在电子表格程序中应用转换,然后将新变量(带标题标签)复制到剪贴板(Windows 用 CTRL-C,Mac 用 CMD-C)。从 “转换类型” 下拉菜单中选择 “剪贴板(Clipboard)”,将新数据粘贴到 “从电子表格粘贴(Paste from spreadsheet)” 框中。关键是新变量的观测数必须与 Radiant 中的数据一致。点击 “存储” 将新变量添加到数据中。
> **注意:** 不推荐使用剪贴板功能进行数据转换,因为它不可重复。
#### 创建
从`转换类型` 下拉菜单中选择 `创建`。这是创建新变量或转换现有变量最灵活的命令,但需要一些基本的 R 语法知识。新变量可以是(活跃)数据集中其他变量的任意函数。以下是一些示例。每个示例中,`=`左侧是新变量的名称,`=`右侧可包含其他变量名称和基本 R 函数。输入命令后按回车查看新变量的汇总统计量。如果结果符合预期,点击`存储` 将其添加到数据集。
> **注意:** 如果从 “选择变量” 列表中选中了一个或多个变量,创建新变量前会先按这些变量对数据分组(见下方示例 1)。如果不希望分组,请确保创建新变量时未选中任何变量
1. 创建等于价格均值的新变量`z`。要按组(如按净度水平)计算价格均值,在创建`z`前从 “选择变量” 列表中选择`clarity`
```r
z = mean(price)
```
2. 创建变量`z`,其值为变量 x 和 y 的差值
```r
z = x - y
```
3. 创建变量`z`,其为变量`x`的转换版本,均值为 0(另见 “转换> 中心化”):
```r
z = x - mean(x)
```
4. 创建逻辑变量`z`,当`x > y`时取值为 TRUE,否则为 FALSE
```r
z = x > y
```
5. 创建逻辑变量`z`,当`x`等于`y`时取值为 TRUE,否则为 FALSE
```r
z = x == y
```
6. 创建变量`z`,其值为变量`x`滞后 3 期的值
```r
z = lag(x,3)
```
7. 创建具有两个水平(即`smaller`和`bigger`)的分类变量
```r
z = ifelse(x < y, 'smaller', 'bigger')
```
8. 创建具有三个水平的分类变量。另一种方法是使用下文描述的 “重编码” 函数
```r
z = ifelse(x < 60, '< 60', ifelse(x > 65, '> 65', '60-65'))
```
9. 将异常值转换为缺失值。例如,如果我们想从名为`sales`的变量中移除等于 400 的最大值,可使用`ifelse`语句,在 “创建” 框中输入以下命令。按回车并点击 “存储” 将`sales_rc`添加到数据中。注意,如果我们在`=`左侧输入`sales`,原始变量将被覆盖
```r
sales_rc = ifelse(sales > 400, NA, sales)
```
10. If a respondent with ID 3 provided information on the wrong scale in a survey (e.g., income in \$1s rather than in \$1000s) we could use an `ifelse` statement and enter the command below in the `Create` box. As before, press `return` and `Store` to add `sales_rc` to the data
```r
income_rc = ifelse(ID == 3, income/1000, income)
```
11. 如果 ID 为 3 的受访者在调查中使用了错误的量表(如收入单位为 1 美元而非 1000 美元),可使用`ifelse`语句,在 “创建” 框中输入以下命令。同样,按回车并点击 “存储” 将`income_rc`添加到数据中
```r
income_rc = ifelse(ID %in% c(1, 3, 15), income/1000, income)
```
12. 如果多名受访者出现相同的量表错误(如 ID 为 1、3 和 15 的受访者),再次使用 “创建” 并输入:
```r
date = parse_date_time(x, '%m%d%y')
```
13. 计算两个日期 / 时间之间的秒数差
```r
tdiff = as_duration(time2 - time1)
```
14. 从日期变量中提取月份
```r
m = month(date)
```
15. 可从日期或日期时间变量中提取的其他属性包括`minute`(分钟)、`hour`(小时)、`day`(日)、`week`(周)、`quarter`(季度)、`year`(年)、`wday`(星期)。对于`wday`和`month`,在调用中添加`label = TRUE`会很方便。例如,从日期变量中提取星期并使用标签而非数字
```r
wd = wday(date, label = TRUE)
```
16. 使用经纬度信息计算两个地点之间的距离
```r
dist = as_distance(lat1, long1, lat2, long2)
```
17. 使用`xtile`命令计算变量`recency`的五分位数。要创建十分位数,将`5`替换为`10`。
```r
rec_iq = xtile(recency, 5)
```
18. 要反转上述 17 中创建的五分位数顺序,使用`rev = TRUE`
```r
rec_iq = xtile(recency, 5, rev = TRUE)
```
19. 要从字符或因子变量的条目中移除文本,使用`sub`移除首个实例,或`gsub`移除所有实例。例如,假设变量`bk_score`的每行在数字前都有字母 “clv”(如 “clv150”)。我们可按如下方式将每个 “clv” 替换为 “”:
```r
bk_score = sub("clv", "", bk_score)
```
注意:对于上述示例 7、8 和 15,在进一步分析前,可能需要将新变量更改为因子类型(另见上文 “更改类型”)
### 清洗数据
#### 移除缺失值
从 `转换类型` 下拉菜单中选择 `移除缺失值` 以删除含一个或多个缺失值的行。`选择变量` 中存在缺失值的行将被移除。点击 `存储` 修改数据。如果存在缺失值,你会看到数据汇总中的观测数发生变化(即`n`的值变化)。
#### 重新排序或移除变量
从 `转换类型` 下拉菜单中选择 `移除/重新排序变量`。拖放变量可重新排序数据中的变量。要移除变量,点击标签旁的×符号。点击 `存储` 应用更改。
#### 移除重复值
数据集中通常有一个或多个变量的值唯一(即无重复)。例如,客户 ID 应唯一,除非数据集包含同一客户的多个订单。要移除重复项,选择一个或多个变量来确定 “唯一性”。从`转换类型` 下拉菜单中选择 `移除重复项`,查看显示的汇总统计量变化。点击 `存储` 修改数据。如果存在重复行,你会看到数据汇总中的观测数发生变化(即`n`和`n_distinct`的值变化)。
#### 显示重复值
如果数据中存在重复项,使用 `显示重复项`可更好地了解在多行中具有相同值的数据点。如果你想在“数据> 查看”标签页中查看重复项,确保将它们存储在不同的数据集中(即**不要**覆盖你正在处理的数据)。如果基于数据中的所有列显示重复项,只会显示重复行中的一行。这些行完全相同,显示 2 行或 3 行没有意义。但如果基于部分变量查看重复项,Radiant 会生成包含**所有**相关行的数据集。
### 扩展数据
#### 扩展网格
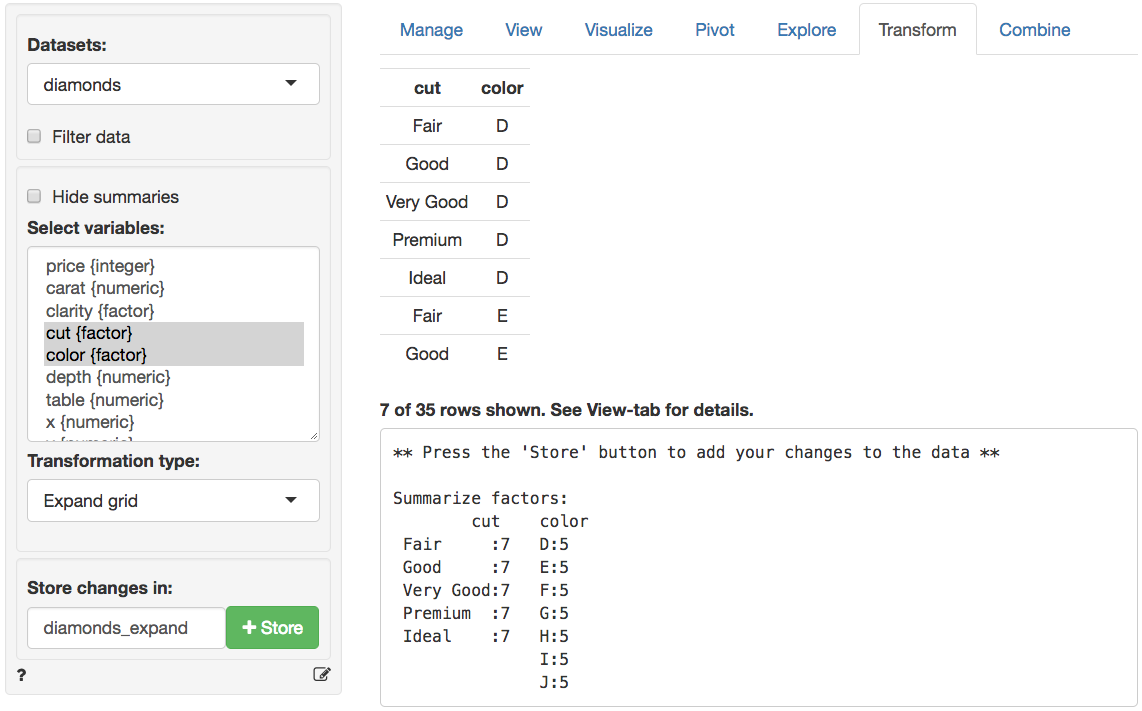
创建包含所选变量所有值组合的数据集。这在生成预测数据集时很有用,例如在“模型> 估计 > 线性回归(OLS)”或“模型> 估计 > 逻辑回归(GLM)”中。假设你想创建包含钻石`cut`和`color`所有可能组合的数据集。从`转换类型` 下拉菜单中选择 `扩展网格`,在 `选择变量` 框中选择`cut`和`color`,从下方截图中可看到有 35 种可能的组合(即`cut`有 5 个唯一值,`color`有 7 个唯一值,因此有 5×7 种组合)。为新数据集命名(如 diamonds_expand),点击 `存储` 按钮将其添加到 `数据集(Datasets)` 下拉菜单中。
#### 表格转数据
将频数表转换为数据集。行数将等于所有频数之和。
### 拆分数据
#### 留存样本
要基于过滤器创建留存样本,从 `转换类型` 下拉菜单中选择 `留存样本`。默认使用活跃过滤器的 `相反` 条件。例如,如果分析的是`date < '2014-12-13'`的观测,且勾选了`反转过滤器` 框,留存样本将包含`date >= '2014-12-13'`的行。
#### 训练变量
要创建可用于(随机)过滤数据集以进行模型训练和测试的变量,从 `转换类型` 下拉菜单中选择 `训练变量`。指定用于训练的观测数(如将 `大小` 设为 2000)或选择的观测比例(如将 `大小` 设为 0.7)。新变量在训练数据中取值为`1`,在测试数据中取值为`0`。
也可选择一个或多个变量用于训练和测试样本的随机分配 `区组化`。这有助于确保例如感兴趣变量的正负案例比例(如 “购买” vs “未购买”)在训练和测试样本中(几乎)相同。
### 整洁数据
#### 汇集列
将多个变量合并为一列。如果加载了`diamonds`数据集,从`转换类型` 下拉菜单中选择 `汇集列` 后,在 `选择变量` 框中选择`cut`和`color`。这将创建新变量`key`和`value`。`key`有两个水平(即`cut`和`color`),`value`包含`cut`和`color`的所有值。
#### 扩展列
将一列 `扩展` 为多列。与 `汇集`相反。有关`整洁数据` 的详细讨论,参见整洁数据说明文档。
### R 函数
有关 Radiant 中用于数据转换的相关 R 函数概述,请参见“数据> 转换” 。