> Determine the appropriate number of segments
The goal of Cluster Analysis is to group respondents (e.g., consumers) into segments based on needs, benefits, and/or behaviors. The tool tries to achieve this goal by looking for respondents that are similar, putting them together in a cluster or segment, and separating them from other, dissimilar, respondents. The researcher compares the segments and provides a descriptive label for each.
### Example: Toothpaste
First, go to the _Data > Manage_ tab, select **examples** from the `Load data of type` dropdown, and press the `Load` button. Then select the `toothpaste` dataset. The dataset contains information from 60 consumers who were asked to respond to six questions to determine their attitudes towards toothpaste. The scores shown for variables v1-v6 indicate the level of agreement with statements on a 7-point scale where 1 = strongly disagree and 7 = strongly agree.
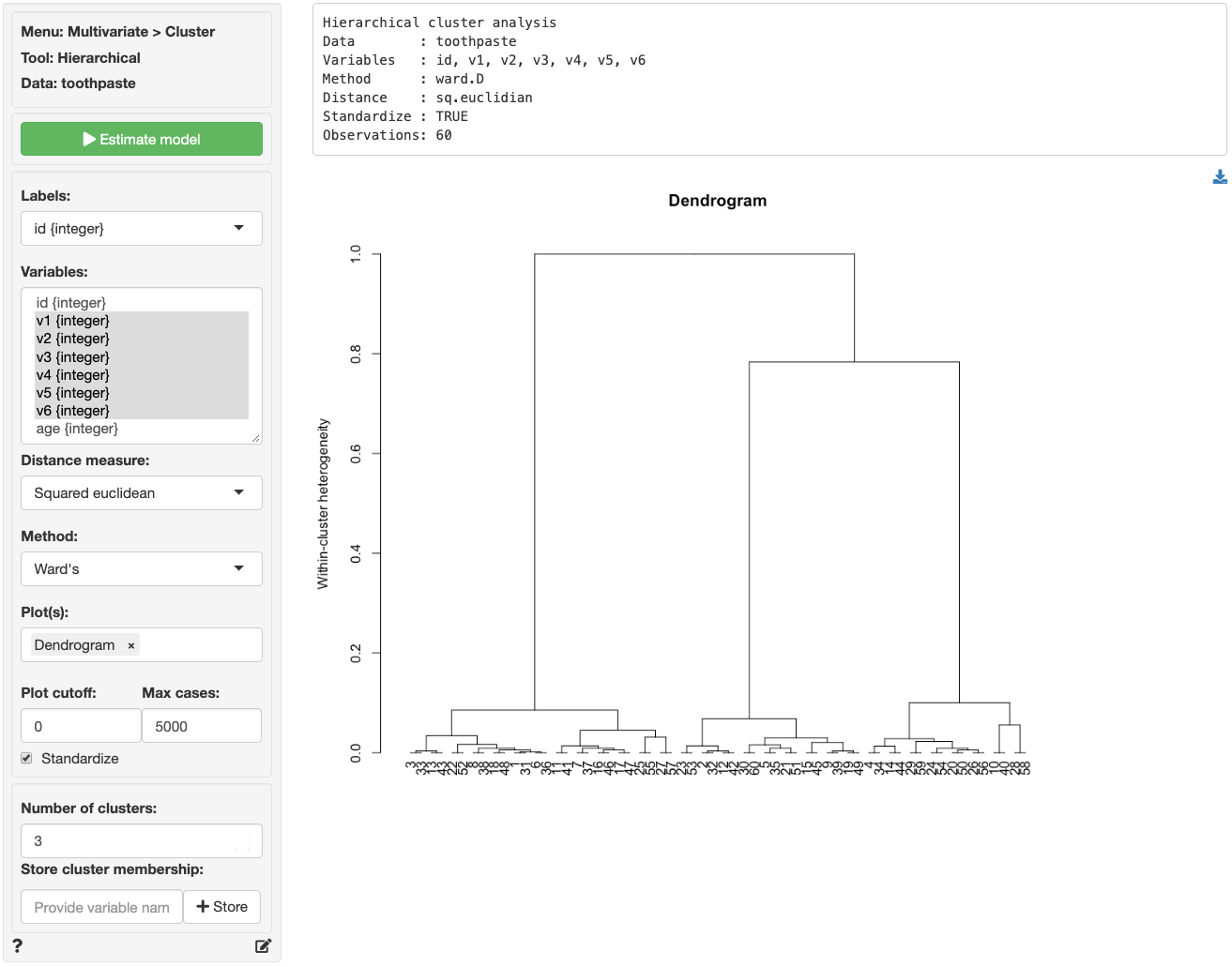
We first establish the number of segments/clusters in the data using Hierarchical Cluster Analysis. Ward’s method with Squared Euclidean distance is often used to determine how (dis)similar individuals are. These are the default values in Radiant but they can be changed if desired. The most important information from this analysis is provide by the plots, so we will focus our attention there.
Select variables v1 through v6 in the Variables box and click the `Estimate` button or press `CTRL-enter` (`CMD-enter` on mac) to generate results. Note that Hierarchical Cluster Analysis can be time-consuming and memory intensive for large datasets. If your dataset has more than 5,000 observations make sure to increase the value in the `Max cases` input to the appropriate number. The Dendrogram shown below provides information to help you determine the most appropriate number of clusters (or segments).
Hierarchical cluster analysis starts with many segments, as many as there are respondents, and in a stepwise (i.e., hierarchical) process adds the most similar respondents or groups together until only one segment remains. To determine the appropriate number of segments look for a _jump_ along the vertical axis of the plot. At that point two dissimilar segments have been joined. The measure along the vertical axis indicates of the level of heterogeneity **within** the segments that have been formed. The purpose of clustering is to create homogeneous groups to avoid segments with heterogeneous characteristics, needs, etc. Since the most obvious _jump_ in heterogeneity occurs when we go from 3 to 2 segments we choose 3 segments (i.e., we avoid creating a heterogeneous segment).
Another plot that can be used to determine the number of segments is a scree-plot. This is a plot of the within-cluster heterogeneity on the vertical axis and the number of segments on the horizontal axis. Again, Hierarchical cluster analysis starts with many segments and groups respondents together until only one segments is left. The scree plot is created by selecting `Scree` (and `Change`) from the `Plot(s)` dropdown menu. If `Plot cutoff` is set to 0 we see results for all possible cluster solutions. To make the plot easier to evaluate, we can set `Plot cutoff` to, for example, 0.05 (i.e. show only solutions that have `Within-cluster heterogeneity` above 5%).
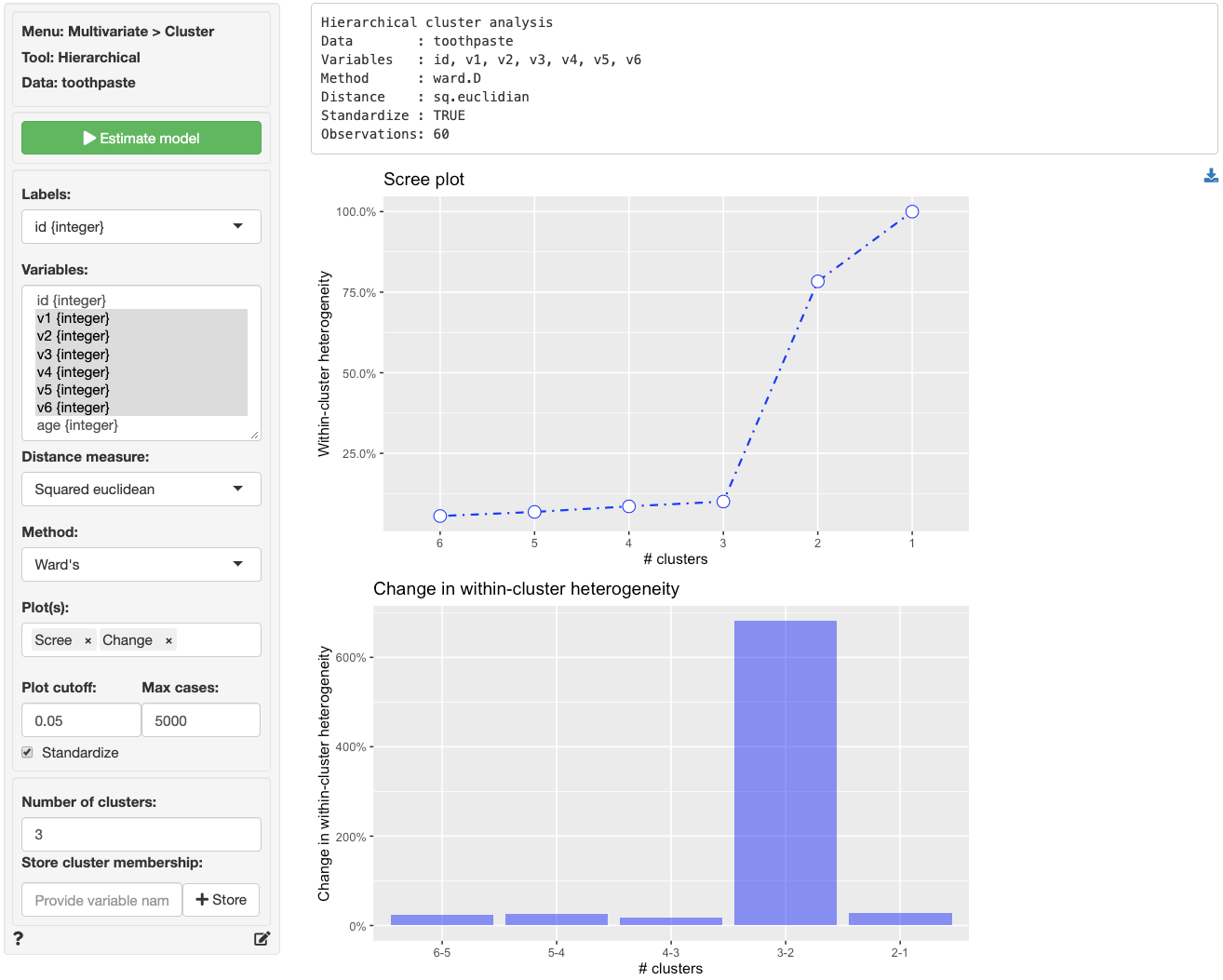
Reading the plot from left-to-right we see that within-segment heterogeneity increases sharply when we move from 3 to 2 segments. This is also clear from the `Change in within-cluster heterogeneity` plot (i.e., `Change`). To avoid creating a heterogeneous segment we, again, choose 3 segments. Now that we have determined the appropriate number of segments to extract we can use either _Cluster > Hierarchical_ or _Cluster > K-clustering_ to generate the final cluster solution.
To download the plots click the download button on the top-right of the screen.
## Additional options
* By default, data will be standardized before it is analyzed. To pass data in its raw form to the estimation algorithm, make sure the `Standardize` box is un-checked
* Hierarchical cluster-analysis (HC) generates numerous clustering solutions. The highest number of clusters is equal to the number of observations in the data (e.g., ever respondent is treated as a separate cluster). The lowest number of clusters evaluated, is equal to 1 (e.g., all respondent are grouped together in a single cluster). Although, HC analysis is often used as a diagnostic tool before generating a final solution using, e.g., K-means, we can also store any specific clustering solution generated using HC. To accomplish this, first choose the `Number of clusters`, then provide a name for the variable that will contain cluster assignment information, and finally, press the `Store` button
* If the data to use for clustering includes variables of type "factor", the `gower` distance will automatically be selected. For more information on the gower distance and R-package see the package vignette
### Report > Rmd
Add code to _Report > Rmd_ to (re)create the analysis by clicking the icon on the bottom left of your screen or by pressing `ALT-enter` on your keyboard.
If a plot was created it can be customized using `ggplot2` commands or with `gridExtra`. See example below and _Data > Visualize_ for details.
```r
plot(result, plots = "change", custom = TRUE) +
labs(caption = "Data used from ...")
```
To add, for example, a sub-title to a dendrogram plot use `title(sub = "Data used from ...")`. See the R graphics documentation for additional information.
### R-functions
For an overview of related R-functions used by Radiant to conduct cluster analysis see _Multivariate > Cluster_
The key function from the `stats` package used in the `hclus` tool is `hclust`.