> 合并两个数据集
Radiant 中提供了六种来自 Hadley Wickham 等人开发的dplyr包的 “连接(join)”(或 “合并(merge)”)选项。
以下示例改编自 Jenny Bryan 的《dplyr 连接函数速查表》,聚焦三个小型数据集(superheroes、publishers和avengers),以说明 R 和 Radiant 中不同的连接类型及其他数据集合并方式。这些数据也可通过以下链接获取 csv 格式文件:
* superheroes.csv
* publishers.csv
* avengers.csv
Superheroes
| name |
alignment |
gender |
publisher |
| Magneto |
bad |
male |
Marvel |
| Storm |
good |
female |
Marvel |
| Mystique |
bad |
female |
Marvel |
| Batman |
good |
male |
DC |
| Joker |
bad |
male |
DC |
| Catwoman |
bad |
female |
DC |
| Hellboy |
good |
male |
Dark Horse Comics |
Publishers
| publisher |
yr_founded |
| DC |
1934 |
| Marvel |
1939 |
| Image |
1992 |
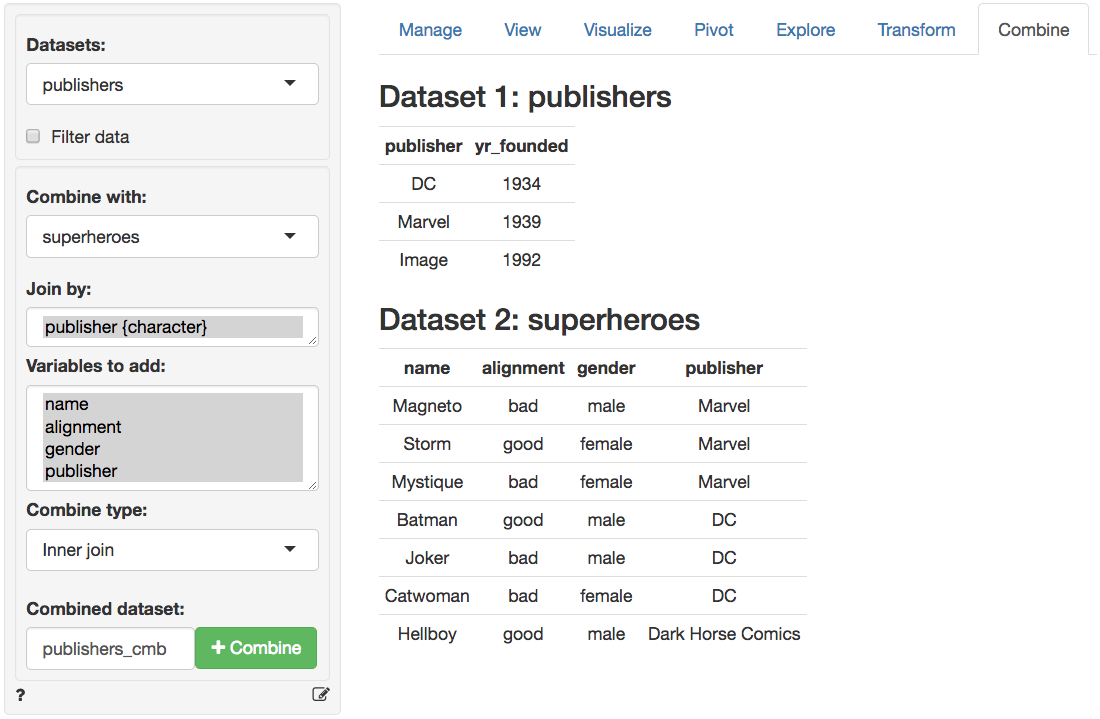
在下方`数据>合并` 标签页的截图中,我们可以看到两个数据集。这两个表格共享 “出版商(publisher)” 变量,该变量会被自动选为连接键。`合并方式` 下拉菜单中提供了不同的连接选项。你也可以在 `合并后的数据集名称` 文本输入框中指定合并后数据集的名称。
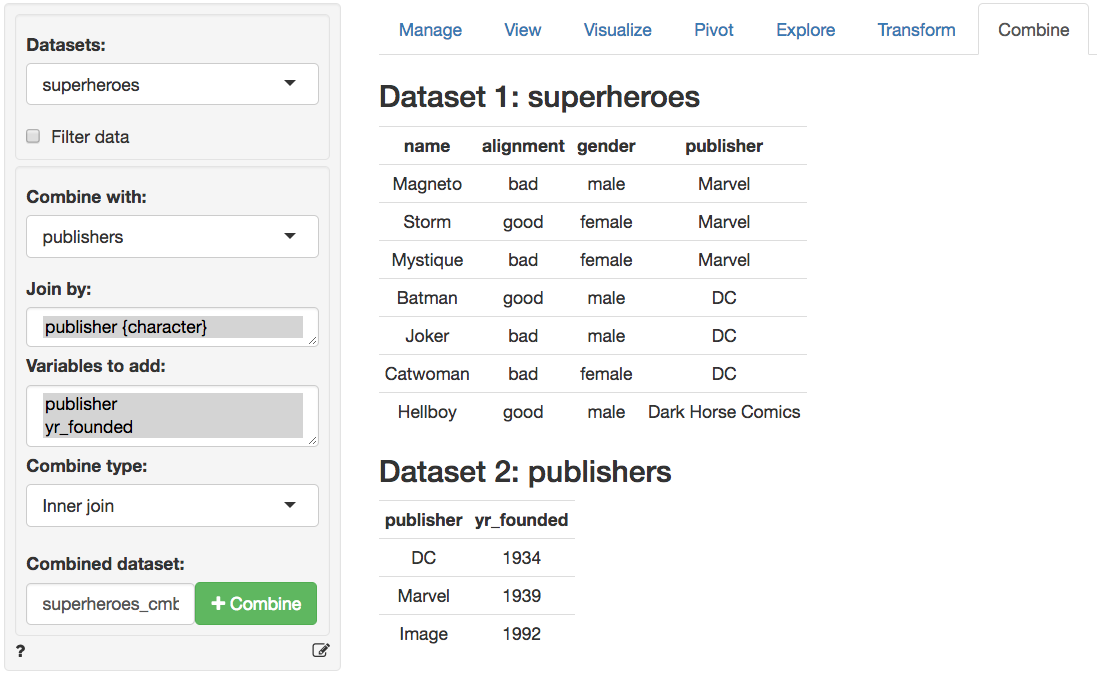
### 内连接(超级英雄 × 出版商)
若 x = 超级英雄数据集,y = 出版商数据集:
> 内连接返回 x 中与 y 有匹配值的所有行,以及 x 和 y 的所有列。若 x 和 y 之间存在多个匹配,所有匹配组合都会被返回。
| name |
alignment |
gender |
publisher |
yr_founded |
| Magneto |
bad |
male |
Marvel |
1939 |
| Storm |
good |
female |
Marvel |
1939 |
| Mystique |
bad |
female |
Marvel |
1939 |
| Batman |
good |
male |
DC |
1934 |
| Joker |
bad |
male |
DC |
1934 |
| Catwoman |
bad |
female |
DC |
1934 |
在上述表格中,我们丢失了 “地狱男爵(Hellboy)”,因为尽管这个英雄出现在`superheroes`数据集中,但其出版商(黑马漫画)未出现在`publishers`数据集中。连接结果包含`superheroes`的所有变量,以及来自`publishers`的 “成立年份(yr_founded)” 变量。我们可以用下方的维恩图可视化内连接:

R(Radiant)命令如下:
```r
# Radiant
combine_data(superheroes, publishers, by = "publisher", type = "inner_join")
# R
inner_join(superheroes, publishers, by = "publisher")
```
### 左连接(超级英雄 × 出版商)
> 左连接返回 x 的所有行,以及 x 和 y 的所有列。若 x 和 y 之间存在多个匹配,所有匹配组合都会被返回。
| name |
alignment |
gender |
publisher |
yr_founded |
| Magneto |
bad |
male |
Marvel |
1939 |
| Storm |
good |
female |
Marvel |
1939 |
| Mystique |
bad |
female |
Marvel |
1939 |
| Batman |
good |
male |
DC |
1934 |
| Joker |
bad |
male |
DC |
1934 |
| Catwoman |
bad |
female |
DC |
1934 |
| Hellboy |
good |
male |
Dark Horse Comics |
NA |
连接结果包含`superheroes`的所有数据,以及来自`publishers`的 “成立年份(yr_founded)” 变量。“地狱男爵” 的出版商未出现在`publishers`中,因此其 “成立年份” 为`NA`。我们可以用下方的维恩图可视化左连接:
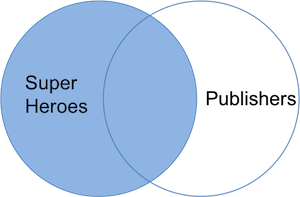
R(Radiant)命令如下:
```r
# Radiant
combine_data(superheroes, publishers, by = "publisher", type = "left_join")
# R
left_join(superheroes, publishers, by = "publisher")
```
### 右连接(超级英雄 × 出版商)
> 右连接返回 y 的所有行,以及 y 和 x 的所有列。若 y 和 x 之间存在多个匹配,所有匹配组合都会被返回。
| name |
alignment |
gender |
publisher |
yr_founded |
| Magneto |
bad |
male |
Marvel |
1939 |
| Storm |
good |
female |
Marvel |
1939 |
| Mystique |
bad |
female |
Marvel |
1939 |
| Batman |
good |
male |
DC |
1934 |
| Joker |
bad |
male |
DC |
1934 |
| Catwoman |
bad |
female |
DC |
1934 |
| NA |
NA |
NA |
Image |
1992 |
连接结果包含`publishers`的所有行和列,以及`superheroes`的所有变量。我们丢失了 “地狱男爵”,因为其出版商未出现在`publishers`中。“图像漫画(Image)” 被保留在表格中,但来自`superheroes`的 “姓名(name)”“阵营(alignment)” 和 “性别(gender)” 变量为`NA`。请注意,连接可能会改变行和变量的顺序,因此在分析中不应依赖这些顺序。我们可以用下方的维恩图可视化右连接:

R(Radiant)命令如下:
```r
# Radiant
combine_data(superheroes, publishers, by = "publisher", type = "right_join")
# R
right_join(superheroes, publishers, by = "publisher")
```
### 全连接(超级英雄 × 出版商)
> 全连接合并两个数据集,保留出现在任一数据集中的行和列。
| name |
alignment |
gender |
publisher |
yr_founded |
| Magneto |
bad |
male |
Marvel |
1939 |
| Storm |
good |
female |
Marvel |
1939 |
| Mystique |
bad |
female |
Marvel |
1939 |
| Batman |
good |
male |
DC |
1934 |
| Joker |
bad |
male |
DC |
1934 |
| Catwoman |
bad |
female |
DC |
1934 |
| Hellboy |
good |
male |
Dark Horse Comics |
NA |
| NA |
NA |
NA |
Image |
1992 |
在这个表格中,我们保留了 “地狱男爵”(即使 “黑马漫画” 不在`publishers`中)和 “图像漫画”(即使该出版商未在`superheroes`中列出),并获取了两个数据集的变量。没有匹配项的观测在来自另一个数据集的变量中被赋值为 NA。我们可以用下方的维恩图可视化全连接:
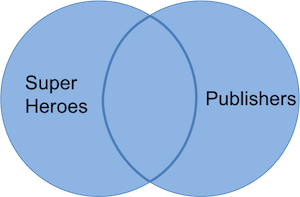
R(Radiant)命令如下:
```r
# Radiant
combine_data(superheroes, publishers, by = "publisher", type = "full_join")
# R
full_join(superheroes, publishers, by = "publisher")
```
### 半连接(超级英雄 × 出版商)
> 半连接仅保留 x 中的列。内连接会为 x 中每个与 y 匹配的行返回一行,而半连接绝不会复制 x 中的行。
| name |
alignment |
gender |
publisher |
| Magneto |
bad |
male |
Marvel |
| Storm |
good |
female |
Marvel |
| Mystique |
bad |
female |
Marvel |
| Batman |
good |
male |
DC |
| Joker |
bad |
male |
DC |
| Catwoman |
bad |
female |
DC |
我们得到了与`内连接`类似的表格,但仅包含`superheroes`中的变量。R(Radiant)命令如下:
```r
# Radiant
combine_data(superheroes, publishers, by = "publisher", type = "semi_join")
# R
semi_join(superheroes, publishers, by = "publisher")
```
### 反连接(超级英雄 × 出版商)
> 反连接返回 x 中与 y 无匹配值的所有行,仅保留 x 中的列。
| name |
alignment |
gender |
publisher |
| Hellboy |
good |
male |
Dark Horse Comics |
现在我们**只**得到了 `地狱男爵`—— 唯一未在`publishers`中找到对应出版商的超级英雄,且未包含 “成立年份(yr_founded)” 变量。我们可以用下方的维恩图可视化反连接:
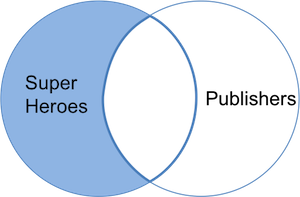
### 数据集顺序
请注意,所选数据集的顺序可能会影响连接结果。如果我们如下设置 `数据> 合并` 标签页,结果如下:
### 内连接(出版商 × 超级英雄)
| publisher |
yr_founded |
name |
alignment |
gender |
| DC |
1934 |
Batman |
good |
male |
| DC |
1934 |
Joker |
bad |
male |
| DC |
1934 |
Catwoman |
bad |
female |
| Marvel |
1939 |
Magneto |
bad |
male |
| Marvel |
1939 |
Storm |
good |
female |
| Marvel |
1939 |
Mystique |
bad |
female |
每个在`superheroes`中有匹配项的出版商都会多次出现,每个匹配项对应一行。除变量和行的顺序外,这与上方显示的内连接结果相同。
### 左连接和右连接(出版商 × 超级英雄)
除行和变量顺序外,`publishers`与`superheroes`的左连接等价于`superheroes`与`publishers`的右连接。同样,`publishers`与`superheroes`的右连接等价于`superheroes`与`publishers`的左连接。
### 全连接(出版商 × 超级英雄)
如你所料,除行和变量顺序外,`publishers`与`superheroes`的全连接等价于`superheroes`与`publishers`的全连接。
### 半连接(出版商 × 超级英雄)
| publisher |
yr_founded |
| DC |
1934 |
| Marvel |
1939 |
通过半连接,交换数据集顺序的影响更为明显。尽管每个出版商有多个匹配项,但仅显示一次。与之对比,内连接中 “若 x 和 y 之间存在多个匹配,所有匹配组合都会被返回”。表格中丢失了出版商 “图像漫画(Image)”,因为它不在`superheroes`中。
### 反连接(出版商 × 超级英雄)
| publisher |
yr_founded |
| Image |
1992 |
仅保留了出版商 “图像漫画”,因为 “漫威” 和 “DC” 都在`superheroes`中。我们只保留了`publishers`中的变量。
### 合并数据集的其他工具(复仇者 × 超级英雄)
当两个数据集具有相同的列(或行)时,还有其他方法可将它们合并为新数据集。我们已使用过`superheroes`数据集,现在尝试将其与`avengers`数据合并。这两个数据集的行数和列数相同,且列名相同。
在下方 “数据> 合并” 标签页的截图中,我们可以看到这两个数据集。此处无需选择变量来合并数据集,`选择变量` 中的任何变量在下方命令中都会被忽略。同样,你可以在 `合并后的数据集` 文本输入框中指定合并后数据集的名称。

### 行绑定
| name |
alignment |
gender |
publisher |
| Thor |
good |
male |
Marvel |
| Iron Man |
good |
male |
Marvel |
| Hulk |
good |
male |
Marvel |
| Hawkeye |
good |
male |
Marvel |
| Black Widow |
good |
female |
Marvel |
| Captain America |
good |
male |
Marvel |
| Magneto |
bad |
male |
Marvel |
| Magneto |
bad |
male |
Marvel |
| Storm |
good |
female |
Marvel |
| Mystique |
bad |
female |
Marvel |
| Batman |
good |
male |
DC |
| Joker |
bad |
male |
DC |
| Catwoman |
bad |
female |
DC |
| Hellboy |
good |
male |
Dark Horse Comics |
如果`avengers`数据集旨在扩展超级英雄列表,我们可以将两个数据集上下堆叠。新数据集有 14 行和 4 列。由于`avengers`数据集中的编码错误(万磁王并非复仇者),新合并的数据集中出现了重复行,这可能是我们不希望看到的。
R(Radiant)命令如下:
```r
# Radiant
combine_data(avengers, superheroes, type = "bind_rows")
# R
bind_rows(avengers, superheroes)
```
### 列绑定
| name...1 |
alignment...2 |
gender...3 |
publisher...4 |
name...5 |
alignment...6 |
gender...7 |
publisher...8 |
| Thor |
good |
male |
Marvel |
Magneto |
bad |
male |
Marvel |
| Iron Man |
good |
male |
Marvel |
Storm |
good |
female |
Marvel |
| Hulk |
good |
male |
Marvel |
Mystique |
bad |
female |
Marvel |
| Hawkeye |
good |
male |
Marvel |
Batman |
good |
male |
DC |
| Black Widow |
good |
female |
Marvel |
Joker |
bad |
male |
DC |
| Captain America |
good |
male |
Marvel |
Catwoman |
bad |
female |
DC |
| Magneto |
bad |
male |
Marvel |
Hellboy |
good |
male |
Dark Horse Comics |
如果数据集为相同超级英雄包含不同列,我们可以将两个数据集并排合并。在 Radiant 中,若尝试绑定同名列,会看到错误消息,这是我们应始终避免的情况。若已知两个数据集的行 ID 顺序相同但列完全不同,此方法可能有用。
### 交集
| name |
alignment |
gender |
publisher |
| Magneto |
bad |
male |
Marvel |
检查两个具有相同列的数据集是否有重复行的好方法是从`合并方式` 下拉菜单中选择 `交集`。`avengers`和`superheroes`数据中确实有一行完全相同(即万磁王)。
R(Radiant)命令与上方所示相同,只需将`bind_rows`替换为`intersect`。
### 并集
| name |
alignment |
gender |
publisher |
| Thor |
good |
male |
Marvel |
| Iron Man |
good |
male |
Marvel |
| Hulk |
good |
male |
Marvel |
| Hawkeye |
good |
male |
Marvel |
| Black Widow |
good |
female |
Marvel |
| Captain America |
good |
male |
Marvel |
| Magneto |
bad |
male |
Marvel |
| Storm |
good |
female |
Marvel |
| Mystique |
bad |
female |
Marvel |
| Batman |
good |
male |
DC |
| Joker |
bad |
male |
DC |
| Catwoman |
bad |
female |
DC |
| Hellboy |
good |
male |
Dark Horse Comics |
`avengers`和`superheroes`的 `并集` 会合并数据集,但会省略重复行(即仅保留万磁王的一行)。这可能是我们此处想要的结果。
R(Radiant)命令与上方所示相同,只需将`bind_rows`替换为`union`。
### 差集
| name |
alignment |
gender |
publisher |
| Thor |
good |
male |
Marvel |
| Iron Man |
good |
male |
Marvel |
| Hulk |
good |
male |
Marvel |
| Hawkeye |
good |
male |
Marvel |
| Black Widow |
good |
female |
Marvel |
| Captain America |
good |
male |
Marvel |
最后,`差集` 会保留`avengers`中不在`superheroes`中的行。若交换输入(即从 `数据集` 下拉菜单中选择`superheroes`,从 `合并对象` 下拉菜单中选择`superheroes`),最终会得到`superheroes`中不在`avengers`中的所有行。两种情况下,万磁王的条目都会被省略。
R(Radiant)命令与上方所示相同,只需将`bind_rows`替换为`setdiff`。
### 报告 > Rmd
通过点击屏幕左下角的图标或按键盘上的`ALT-enter`,向*报告 > Rmd*添加代码以(重新)创建合并后的数据集。
更多相关讨论请参见《R for data science》中关于关系数据的章节点击查看和Tidy Explain。
### R 函数
有关`combine_data`函数的帮助,请参见*数据 > 合并*。